
Post-training is the process of adapting a pre-trained language model to perform better on a specific task or domain. While foundation models are powerful out of the box, they often need refinement to excel at particular applications.
In this guide, we'll learn how to post-train an LLM using the "20 Questions" game (guessing animal names) as our learning example. This game provides a clear, measurable outcome—winning by guessing the correct answer—making it an ideal case study for understanding post-training techniques.
The Problem with Traditional Metrics
When post-training an LLM, it's crucial to measure what actually matters for your task. Standard evaluation metrics often measure one thing: does the output resemble good outputs?
- Cosine similarity asks: "Is this response close to good responses in embedding space?"
- BERTScore asks: "Does this response share semantic content with good responses?"
Neither asks: "Is it actually able to guess correctly?"
In the 20 Questions game, "working" means guessing the animal correctly with few questions. A model can perfectly mimic the style of good gameplay while being strategically terrible.
1┌─────────────────────────────────────────────────────┐
2│ The Evaluation Gap │
3├─────────────────────────────────────────────────────┤
4│ │
5│ Traditional Metrics Outcome Metrics │
6│ ─────────────────── ─────────────── │
7│ Cosine similarity: 0.89 Success rate: 62% │
8│ BERTScore: 0.84 Avg questions: 14.2 │
9│ "Looks great!" "Needs work." │
10│ │
11│ ↑ Measures style ↑ Measures success │
12│ │
13└─────────────────────────────────────────────────────┘This is a core insight for post-training: when you have a measurable outcome, optimize for it directly instead of hoping that stylistic similarity translates to performance.
Why Post-Training Matters
Let's see how this plays out in our 20 Questions example. The optimal strategy from an information theory perspective:
With 90 possible animals, the theoretical minimum is log2(90) = 6.5 questions. Each perfect binary question cuts the remaining possibilities in half. In practice, 7-8 questions is achievable with a good strategy.
But LLMs don't naturally think about information gain. They generate text that seems reasonable based on patterns in training data. The model might ask:
- "Is it cute?" — Subjective, low information. Doesn't reliably split the space.
- "Is it a mammal?" — Objective, high information. Splits roughly 50/50.
A model trained on example games learns to ask questions that look like good questions. It doesn't learn which questions actually are good for narrowing down possibilities.
1┌─────────────────────────────────────────────────────┐
2│ Question Quality: Information Gain │
3├─────────────────────────────────────────────────────┤
4│ │
5│ 90 animals │
6│ │
7│ "Is it cute?" │
8│ Yes: 47 No: 43 (biased, subjective) │
9│ │
10│ "Does it live in water?" │
11│ Yes: 28 No: 62 (objective, ~splits) │
12│ │
13│ "Is it larger than a dog?" │
14│ Yes: 41 No: 49 (objective, good split) │
15│ │
16└─────────────────────────────────────────────────────┘This is why post-training matters. Supervised fine-tuning teaches imitation. More advanced post-training techniques can teach strategy and optimization.
Measuring What Matters
Before applying any post-training technique, you need an evaluation script that measures actual performance. For our 20 Questions example, this means actually playing the game:
- Pick a target animal from the 90 possibilities
- The fine-tuned model asks questions
- GPT-4.1-mini simulates a child answering yes/no
- Continue until the model guesses or hits 20 questions
- Record: success (correct guess) and efficiency (questions used)
The efficiency score formula captures both dimensions:
1efficiency = success_rate × (1 - avg_questions / 20)A model that wins 100% of games in 10 questions scores higher than one that wins 100% in 15 questions. A model that wins 80% in 8 questions might beat one that wins 100% in 14 questions.
This becomes your ground truth for comparing training approaches.
Post-Training Approaches: A Spectrum
There's a spectrum of approaches for post-training LLMs, from simple data curation to advanced reinforcement learning techniques. We'll explore these using our 20 Questions example:

Level 1: Weighted Supervised Learning
The quickest win: oversample efficient games in your training data. If you have 1000 example games and 100 of them win in under 8 questions, duplicate those 100 examples 5x. The model sees more examples of efficient play.
This requires no new infrastructure—just data preprocessing.
Level 2: Direct Preference Optimization (DPO)
Create preference pairs: an efficient game (wins in 7 questions) vs an inefficient game (wins in 14 questions) for the same target animal. Train the model to prefer the efficient trajectory.
DPO is powerful because it works offline on existing data. No reward model needed, no online rollouts. You just need pairs of "better" and "worse" examples.
1# DPO training data format
2{
3 "prompt": "Target: elephant. Game history: ...",
4 "chosen": "Is it larger than a car?", # Led to win in 7 questions
5 "rejected": "Is it gray?" # Led to win in 14 questions
6}Level 3: Reinforcement Learning (GRPO/PPO)
For more advanced post-training, reinforcement learning techniques allow the model to learn from actually playing. In our 20 Questions example, the model plays thousands of games against a simulated opponent, with reward signals based on outcomes.
This is where the magic happens—the model discovers strategies that weren't in the training data.
GRPO (Group Relative Policy Optimization) is particularly effective for LLM post-training. It samples multiple responses for each prompt, ranks them by reward, and updates the policy to increase the probability of better responses relative to worse ones.
Post-Training in Practice: LLM-in-the-Loop
For our 20 Questions example, the GRPO implementation uses an interesting trick: an external LLM simulates the opponent during training.
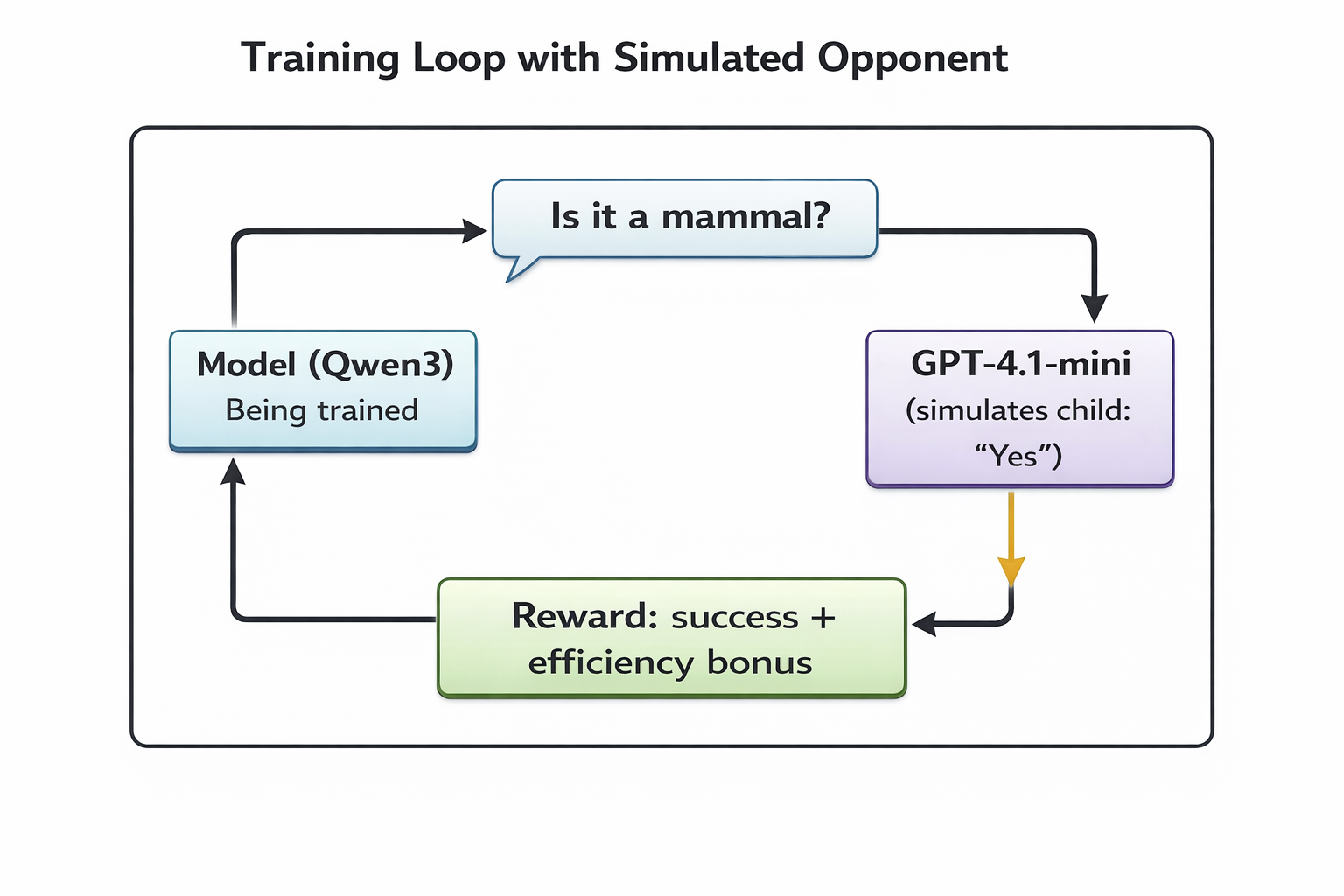
The setup:
- Base model: Qwen3-4B with LoRA adapters
- Training framework: TRL's GRPOTrainer
- Opponent: GPT-4.1-mini answering yes/no based on target animal
- Reward: +1 for correct guess, scaled by efficiency
The model plays thousands of games. Each game produces a trajectory (sequence of questions and answers) with a reward. GRPO uses these to update the policy—increasing the probability of question sequences that led to fast wins.
1from trl import GRPOTrainer, GRPOConfig
2
3config = GRPOConfig(
4 output_dir="./grpo-20questions",
5 num_train_epochs=3,
6 per_device_train_batch_size=4,
7 gradient_accumulation_steps=4,
8 learning_rate=1e-5,
9 num_generations=4, # Sample 4 responses per prompt
10)
11
12def reward_function(completions, target_animal):
13 rewards = []
14 for completion in completions:
15 result = simulate_game(completion, target_animal)
16 if result.success:
17 # Reward scales with efficiency
18 reward = 1.0 * (1 - result.questions_asked / 20)
19 else:
20 reward = -0.5
21 rewards.append(reward)
22 return rewards
23
24trainer = GRPOTrainer(
25 model=model,
26 config=config,
27 reward_funcion=reward_function,
28 train_dataset=dataset,
29)
30
31trainer.train()The key insight: the reward function encodes exactly what we care about. The model figures out how to achieve it.
Don't Forget the Audit
Before expensive SFT training runs, audit your synthetic data for coverage gaps.
A subtle failure mode: your training data might have zero successful games for certain animals. The model never sees what "winning" looks like for a giraffe, so it can't learn to guess giraffe. So, you must ensure that your training data has enough successful games for all animals.
The Takeaway
Post-training an LLM effectively requires measuring what actually matters for your task. When your task has an objective outcome, measure that outcome directly.
The full post-training pipeline:
- Audit data → Catch coverage gaps early
- Supervised fine-tuning → Establish baseline behavior
- Outcome evaluation → Measure what matters
- Advanced optimization (DPO/GRPO) → Optimize for outcomes, not imitation
- Re-evaluation → Verify improvement
Each step builds on the previous. The model doesn't just learn to look like it's performing well. It learns to actually perform well.
That's the power of effective post-training: moving from behavioral mimicry to outcome optimization. This type of post-training is also used for improving thinking abilities of frontier LLMs.