
In this blog, we will be covering the following topics for building a multi AI-Agent system:
- What qualifies as an AI agent?
- Single vs Multi AI-Agent systems
- Tool / Function Calling
- Cost considerations
- Structured outputs
- Prompting techniques
- How to think about orchestration and delegation of tasks
- Choosing the right model
- Batching vs real-time
- Rate limits
- Observability tools, debugging and evals
What qualifies as an AI agent?
An AI agent is a system where artificial intelligence actively controls program flow and decision-making. The hallmark of an AI agent is its ability to determine "what happens next" rather than following pre-programmed logic. This is typically implemented through tool calling - where the Large Language Model (LLM) is given access to a set of tools that it can employ to accomplish tasks. These tools can range from simple information retrieval functions to complex AI-powered capabilities that can both access and modify data.
This is distinct from systems that merely use LLMs within a predetermined workflow - even if they leverage AI, they don't qualify as true AI agents if their logic flow is hardcoded rather than dynamically determined by the AI itself.
Single vs Multi AI-Agent systems
A multi-agent system emerges when we integrate AI-powered tools into an LLM's toolkit, enabling multiple AI components to collaborate seamlessly. This classification also applies to systems where multiple AI prompts are fed each other's outputs, enabling them to "chat" with each other. In both scenarios, the result is a sophisticated network of AI entities working in concert to achieve complex objectives.
Single AI-agent flow
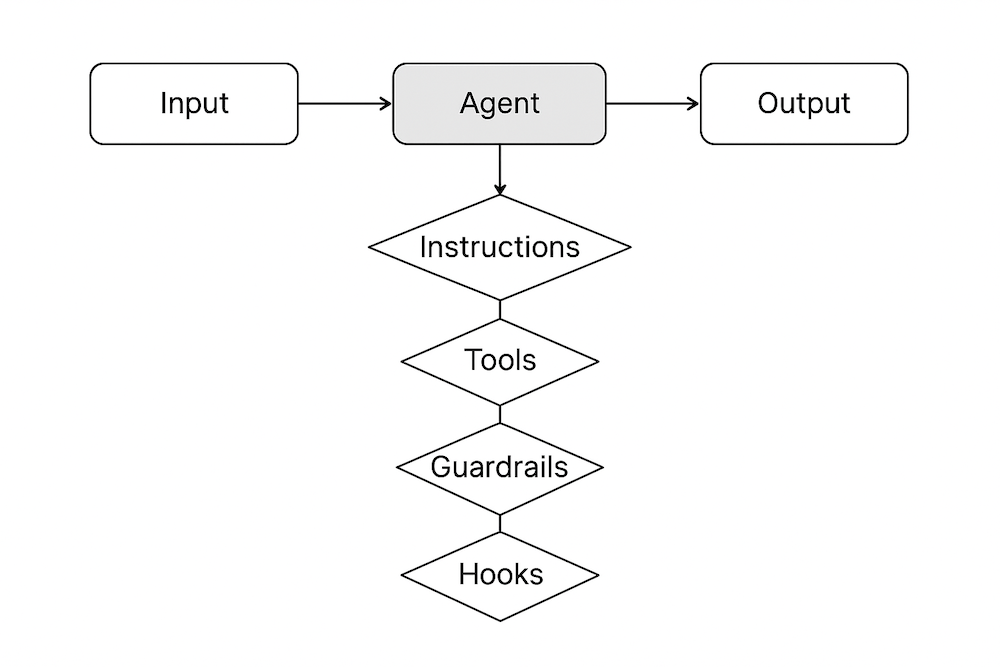 (
(Multi AI-agent flow
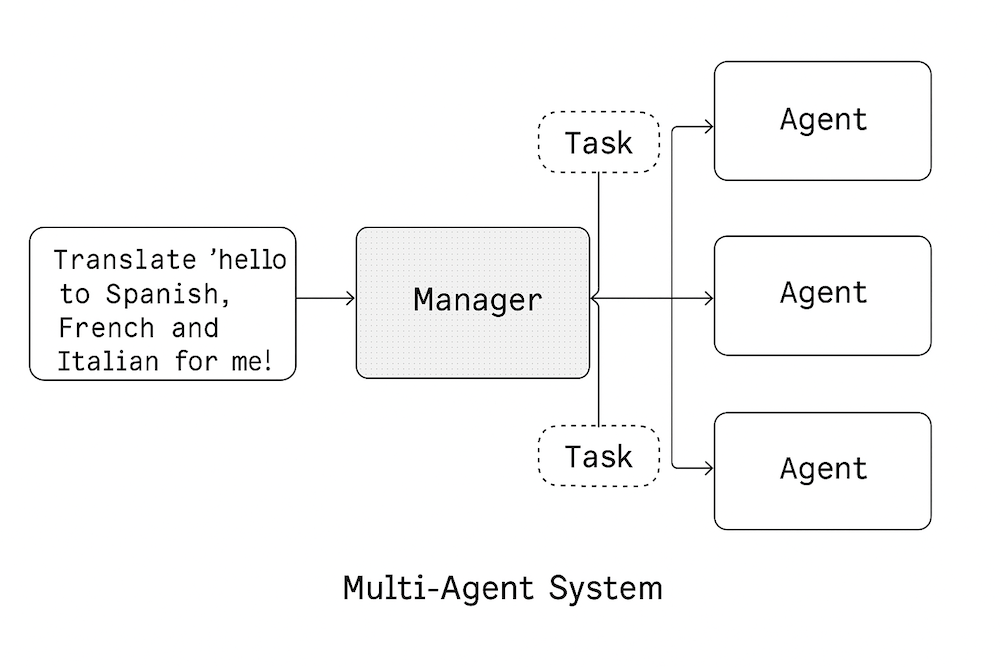 (
(In the multi-agent flow, the "manager" agent can interact with the "worker" agents to complete the task. In this case, we have three worker agents - one for Spanish, one for French and one for Italian translations.
Tool / Function Calling
Tool calling enables LLMs to execute functions you program and process their results. For example, a math function that takes "1+2" and returns "3" allows the LLM to do accurate calculations instead of hallucinating results.
Serial vs Parallel tool calling
LLMs can call multiple functions simultaneously or sequentially. In a recipe application with getMealIdea and getIngredientsForMeal tools, the LLM might call getMealIdea in parallel to generate multiple meals, then use those results to call getIngredientsForMeal. This is illustrated in the diagram below:
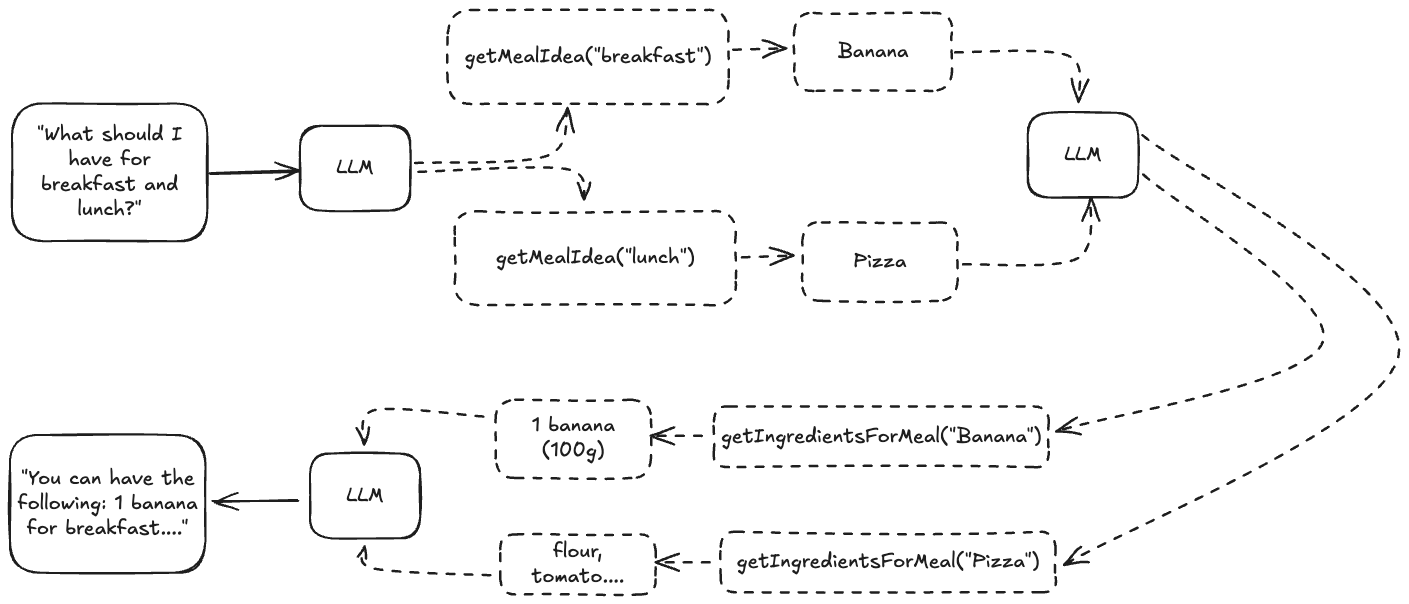
Error handling
If a tool throws an error (for any reason), instead of stopping the agentic flow, we can convert the error to a string and then pass that error state to the LLM. For example, in the above diagram, if the getMealIdea("breakfast") function call failed, we can tell the LLM: "Failed execution. Please try again". This way, the LLM will probably retry the same function call, and this way you don't waste your tokens that were used up in the flow.
Implementing tool calling
Here are two useful resources for implementing tool calling:
Cost considerations
Running AI agents can be very expensive, because tool calling can quickly escalate LLM costs since each tool response requires sending the entire conversation context back to the LLM, resulting in repeated token charges.
Consider our meal recommendation example with three tool call iterations:
Initial request:
- System prompt: 1000 tokens
- User prompt: 9 tokens (requests meal for breakfast and lunch)
- LLM response: 36 tokens (calls
getMealIdeafor breakfast/lunch)
After getMealIdea results:
- Previous context: 1045 tokens
- Tool response: 4 tokens
- LLM response: 40 tokens (calls
getIngredientsForMeal)
After getIngredientsForMeal results:
- Previous context: 1089 tokens
- Tool response: 50 tokens
- Final LLM response: 200 tokens
Total cost: 4,202 input tokens + 276 output tokens
As tool complexity and call frequency increase, costs scale non-linearly due to this context accumulation pattern.
Cost reduction strategies:
- Prioritize parallel tool calls - Instruct the LLM in your system prompt to use parallel over serial execution whenever possible
- Set tool call limits - Define maximum serial tool call thresholds in your system prompt. For example "You can only do tool calls in serial 10 times in a row, so plan your tool calls accordingly."
- Combine related tools - Design multifunctional tools (e.g., merge
getMealIdeaandgetIngredientsForMealinto a single comprehensive tool) - Summarize large contexts - Use a smaller model to compress conversation history when context becomes unwieldy. Make sure to only summarize non system prompt parts of the context, and to keep the system prompt part as is.
Structured outputs
Structured outputs enforce JSON schema compliance, enabling reliable control flow based on LLM responses. Instead of parsing unpredictable text, you get guaranteed JSON structure.
Example use case: Content moderation
You can use structured outputs to implement a content moderation tool. Here's an example of the JSON schema you can use:
1{
2 "offensive": true,
3 "reason": "Contains profanity and hate speech"
4}Your code can then reliably branch logic based on the offensive boolean value.
Key applications in agent systems:
- AI-powered tools / APIs - Tools / APIs that are AI powered can match expected JSON schemas
- Decision-making agents - Reliable branching logic (like we saw above)
- Multi-agent coordination - Standardized communication between agents: If an agent needs to pass information to another agent, it can return a JSON with the information to pass as well as the next agent to call. This is indeed similar to tool calling, the difference being that we need not need to pass back a response to the LLM that decided to call the next agent.
OpenAI's structured outputs guide provides implementation details.
Prompting techniques
Below are some of the most important prompting techniques that I have come across while building multi-agent systems.
Using XML
XML tags provide clear structure and organization for your prompts. Here's an effective system prompt template:
1"""
2You are a helpful assistant.
3
4<Task>
5....
6</Task>
7
8<Planning method>
9....
10</Planning method>
11
12<Examples>
13<Example 1>
14....
15</Example 1>
16
17<Example 2>
18....
19</Example 2>
20</Examples>
21
22<Important>
23....
24</Important>
25
26<Output format>
27....
28</Output format>
29"""Benefits:
- Clear separation - Each section has a defined purpose and boundary
- Token efficiency - XML tags replace verbose descriptors like "Below are examples" or "This is the start of example 1"
- Universal support - OpenAI, Google, and Anthropic all recommend XML tags in prompts
Adding examples
Few-shot examples are the single most effective lever for steering LLM behaviour because they demonstrate—rather than describe—the pattern you want the model to follow.
- Use complete I/O pairs - Each example should show the full input, the full tool call (if any), and the expected output. Partial snippets force the model to guess the missing structure.
- Keep it realistic - Pick real-world edge cases from your logs (after removing any sensitive data). The model generalises best when scenarios look authentic.
- Small > clever - Two or three short, on-point examples beat one giant "master" example. Long or overly smart examples increase token cost without commensurate benefit.
- Order by recency or difficulty - Place the harder or more likely cases last. The model tends to pay more attention to the most recent context.
- Annotate with hidden comments - You can smuggle developer notes inside XML comments (< !-- like this -- >). LLMs ignore them at inference time but your teammates will thank you.
Pro tip: When costs matter, distil your original few-shot prompt into a synthetic one-shot example using a cheaper model. You keep most of the performance while cutting tokens.
Effective tool descriptions
Poor tool metadata is the #1 reason agents hallucinate arguments. A good description has four parts:
- Name: Unique, verb-centric, snake_case so that the purpose is obvious. For example,
generate_itinerary. - Purpose sentence: First line answers when to call the tool, in natural language. For example, "Use this to build a day-by-day travel plan."
- Arguments schema: A tight JSON schema with types and semantic ranges. For example,
{"city": "string", "days": "int (1-14)"}. - Positive / negative calls: At least one example of correct usage and one of when not to call (this is the second sentence in the description field).
1{
2 "name": "generate_itinerary",
3 "description": "Use this to build a day-by-day travel plan. Do NOT call if the user only asks for flight prices.",
4 "parameters": {
5 "type": "object",
6 "properties": {
7 "city": {"type": "string", "description": "Destination city"},
8 "days": {"type": "integer", "minimum": 1, "maximum": 14}
9 },
10 "required": ["city", "days"]
11 }
12}You can even extend the description field to include examples of input and outputs if needed.
Adding escape options for LLM
LLMs tend to be overly accommodating and will attempt to fulfill any request, even when they should refuse or acknowledge limitations. Explicitly providing "escape routes" prevents hallucination and inappropriate responses.
Example 1: Rejecting off-topic requests For a meal recommendation agent, clearly define boundaries in your system prompt:
1"""
2<Important>
3If the user asks for something unrelated to meal recommendations, respond with: "Sorry, I cannot help with that."
4</Important>
5"""Example 2: Handling impossible tasks When building agents that query documents, prevent hallucination by providing a structured format for "not found" scenarios:
1"""
2<Output format>
3When information is found:
4{
5 "found": true,
6 "result": "..."
7}
8
9When information is not found:
10{
11 "found": false,
12 "result": null
13}
14</Output format>
15"""This structured approach lets your application handle missing information gracefully rather than displaying hallucinated results.
Avoid UUIDs
Universally Unique Identifiers are great for databases but terrible for LLM contexts:
- Token bloat - A single UUID (550e8400-e29b-41d4-a716-446655440000) is 18 tokens.
- Zero signal - They carry almost no semantic meaning; the model cannot compress them efficiently.
- Cache misses - Re-using shorter, deterministic IDs (e.g. u123) unlocks higher hit rates in caching layers.
This means that if you are injecting objects from your database into the LLM context, you will have to create a mapper function which will convert the UUIDs in the object to shorter IDs.
Adding time
LLMs do not know what the current time is, so, user queries that require time-based logic will not work. To solve this, you can add the current time at the end of the system prompt:
1"""
2...rest of the prompt
3
4<Current time>
5User timezone: 18:01:45, Wednesday, 2nd July 2025
6UTC timezone: 12:01:45, Wednesday, 2nd July 2025
7</Current time>
8"""It is important to provide both, the user's timezone and the UTC timezone because other context data in your prompt maybe in UTC timezone, but the user's query will refer to time in their local timezone.
How to think about orchestration and delegation of tasks
Going from broad to narrow
Start with a planner agent that receives the user's goal and explodes it into a task graph.
- Decompose the goal - The planner breaks the request into bite-sized tasks (nodes).
- Choose an executor for each node - A node can be
- a tool (deterministic function),
- another specialist agent, or
- the planner itself.
- Order & parallelise - The planner adds edges that encode dependencies, letting independent nodes run in parallel while serialising the rest.
- Explain the plan - For every node it must emit a short rationale: why this task and why this executor? These notes fuel later reflection.
- Limit recursion - Impose a hard depth cap (e.g. 3) to stop runaway task-splitting.
All agents read from and write to a shared context store that tracks:
- user_query - Immutable reference for every agent
- task_graph - Full DAG with status flags (pending, running, done, failed)
- results - Outputs keyed by task ID
Because the context can balloon, apply size-control tactics early:
- Drop transient fields once a task is finished,
- Chunk long results into object storage and keep only pointers,
- Summarise low-value history with a cheaper model.
Here is an example of a rough structure of a system prompt that can be used for the planner agent. It will need to be changed based on your application's data most likely, but nonetheless, it is a good starting point:
1"""
2You are **PlannerAgent**.
3Your responsibility is to turn a single user goal into a DAG (directed acyclic graph) of executable tasks.
4
5<Definitions>
6• *Task* - The smallest unit of work that can be handled by one executor.
7• *Executor* - Either a deterministic tool (e.g. get_weather), a specialist agent
8 (e.g. TranslatorFR), or "self" if you will do the step directly.
9</Definitions>
10
11<Objective>
121. Decompose the user's goal into at most **7** tasks.
132. Add dependency edges so that independent tasks can run in parallel.
143. For each task provide a one-sentence **rationale** explaining:
15 - why the task is needed
16 - why that executor is appropriate.
174. **Specify the exact arguments** (if any) the executor should receive.
185. Enforce a **maximum recursion depth of 3** when splitting tasks.
196. Use short, deterministic IDs (`t1`, `t2`, …) — **never** UUIDs.
20</Objective>
21
22<Available executors>
23{tools_and_agents_json}
24</Available executors>
25
26<Shared context schema>
27You can read (but not delete) these top-level keys:
28{
29 "user_query": "...",
30 "task_graph": { /* previous runs if any */ },
31 "results": { /* completed task outputs */ }
32}
33</Shared context schema>
34
35<Output format>
36Return one raw JSON object with this exact shape:
37
38{
39 "tasks": [
40 {
41 "id": "t1",
42 "description": "...",
43 "executor": "<tool | agent | self>",
44 "args": { // literal values or references
45 "city": "Paris",
46 "days": 3
47 },
48 "rationale": "...",
49 "depends_on": []
50 },
51 {
52 "id": "t2",
53 "description": "...",
54 "executor": "<tool | agent | self>",
55 "args": { // pull 'itinerary' from t1's output
56 "text": "<<t1.itinerary>>"
57 },
58 "rationale": "...",
59 "depends_on": ["t1"]
60 }
61 // … up to t7
62 ],
63 "graph_depth": <int>,
64 "estimated_parallel_groups": <int>
65}
66
67Reference rules:
68- Any `args` value wrapped in `<< >>` is a reference to an earlier task's output.
69- The planner must add that earlier task's ID to `depends_on`.
70- If the referenced task returns a single primitive, use `<<task_id.result>>`.
71- Nested references (t3 → t2 → t1) are allowed but depth ≤ 3 overall.
72</Output format>
73
74<Style rules>
75- Keep each rationale ≤ 25 tokens.
76- Output *raw JSON* (no markdown).
77- Be deterministic: given the same goal and executors, always produce the same plan.
78
79<Current time>
80User timezone: {user_local_time}
81UTC timezone: {utc_time}
82</Current time>
83"""Reflection agent
After each major step—or just before returning to the user—a reflection agent reviews the current state:
- Goal fit - Does the partial or final output satisfy the original intent?
- Correctness - Spot factual, logical, or schema errors.
- Efficiency - Could a simpler or cheaper plan have worked?
It receives only three inputs:
1{
2 "user_query": "...",
3 "task_graph": "...", // with rationales
4 "draft_output": "..."
5}and returns a critique object:
1{
2 "pass": false,
3 "issues": [
4 "Breakfast calories missing",
5 ],
6 "suggestions": [
7 "Call getNutritionFacts for breakfast",
8 ]
9}- If
passistrue, the system replies to the user. - If
passisfalse, the planner consumes suggestions, revises the graph, and tries again—usually with tighter tool limits to avoid infinite loops.
Coupling a planner (for construction) with a reflection agent (for critique) yields a modular, self-correcting and cost-aware multi-agent framework.
Choosing the right model
Here is a table that can help you think about model selection:
| Decision lever | When to choose cheaper / smaller | When to choose larger / multimodal |
|---|---|---|
| Prompt length | ≤ 4 k tokens context | > 8 k tokens or heavy cites |
| Task complexity | Pattern-matching, CRUD-style tool glue | Open-ended reasoning, novel synthesis |
| Latency target | < 300 ms end-to-end | User is willing to wait > 1 s |
| Cost ceiling | Penny-sensitive use cases, high queries per second | Low-throughput, high-value workflows |
Practical playbook:
- Start with the most capable model available to you.
- Collect data about how the model performs for various queries (these are called evals). The more evals you collect, the better. For example, collect 50 evals for easy cases, 50 for medium cases and 100 for edge cases (see the next section on observability tools that can help you collect evals).
- For each agent, rerun the evals on a smaller model, and pick the smallest model that gives a score of > 95% on the evals.
Batching vs real-time
LLM providers offer batch APIs that reduce costs by 50% with identical quality, but come with trade-offs:
Batch processing:
- Pros: 50% cost reduction, same quality
- Cons: Up to 24-hour delays, complex integration
Ideal for non-time-critical tasks:
- Background evals and classification
- High-value workflows where users accept delays
- Note: Small batches often complete in minutes, not hours
Implementation resources:
- OpenAI's batching guide
- Open source server that provides the real time API interface on top of the batching APIs
Rate limits
OpenAI and most providers enforce per-minute caps on requests, tokens, and sometimes concurrent generations.
| Limit type | Typical default | Mitigation |
|---|---|---|
| RPM (req / min) | 3k-20k | HTTP 429 back-off |
| TPM (tokens / min) | 100k-300k | Summarise context, HTTP 429 back-off |
Mitigation: For queries below TPM limits, implement HTTP 429 exponential back-off. For queries exceeding TPM, reduce context size through summarization techniques.
Note: The actual rate limits vary based on provider, and their usage tiers. For example, when you first sign up for OpenAI, you may have a TPM of 30k, but once you spend a certain amount on the platform, this value is increased to >100k.
Observability tools, debugging and evals
Here are some recommended tools for building multi-agent systems:
- CrewAI - A robust framework for multi-agent orchestration
- Langfuse - Comprehensive LLM observability and evaluation tracking
- AgentGraph - Tool calling with visual flow diagrams (Blog post)
- LLMBatching - Provides an easy interface to batch processing
Note: While many other excellent tools exist, these recommendations are based on personal experience. Disclosure: I am the creator of AgentGraph and LLMBatching.